


How serverless works:
Serverless means literally “without server” and it refers to a way to deploy and execute applications where the owner of the application doesn’t have to worry about the server and infrastructure used to serve it. The only responsibility of developers is to write the code needed for the application to work properly and the cloud provider is the one who has to dynamically provision the server, deploy the application in it, and make it work.
Because the code is totally independent of the platform and server on which it will be deployed, the developer doesn’t need to define endpoints or listeners to communicate with the outside world, instead of this, the cloud provider is the one responsible for providing the means to communicate with other services using events that trigger the execution of the application logic.
Some of the biggest advantages of using serverless are:
- The code of the application is completely independent of the server in which it will be deployed.That means that there is nothing in the code related to the server nor infrastructure, in other words, the business code is completely decoupled from the server dependent code and this allows to deploy the same code in any platform without touching any line of code.
- The owner of the service doesn’t have to worry about updates or the maintenance of the servers because they are part of the infrastructure managed by the cloud provider. This could represent a strong cost saving in the overall budget.
- Scalability of the application is managed automatically by the cloud provider and can be scaled down to 0 in the case of the application not having any traffic. This means that the cost of the application could be 0 when it is not in use allowing a pay per use billing model.
However, one of its main features is also one of its biggest disadvantages, and this is because, as we have already said, the cloud provider is responsible for dynamically provisioning the infrastructure needed to deploy the application and its autoscaling, and because of this, it is very coupled to the cloud provider and could lead to the well-known problem called “vendor lock-in”.
This lock-in is not present in the application code but it is present in the different components needed to communicate with the application such as message queues, datastores, gateways, etc.. because they have to be the ones available in the infrastructure of the cloud provider chosen.
How Knative can help
Knative arises as an alternative to avoid this vendor lock-in in the serverless world.
Knative was developed by Google in collaboration with many other companies such as Pivotal, IBM, Red Hat, and SAP and it was released as an open-source project under Apache 2.0 license in 2015.
The main goal of this project was precisely to offer a serverless platform built over Kubernetes, to avoid the vendor lock-in and this way allow the development of a serverless platform that can be hosted in any of the main cloud providers without making any changes in the code.
The use of Kubernetes allows a company to deploy all the components needed for the application such as message queues or gateways inside the Kubernetes cluster and make it independent of the cloud provider infrastructure.
In addition to Kubernetes, Knative uses Istio, an open-source service mesh, in its serving module to provide routing functionalities which can be used to create blue-green deployments or canary releases.
Modules
Knative offers two different modules to allow the user application to communicate with the outside world. Serving and Eventing. These modules can be used independently or can be used together depending on the capabilities required by the application.
Serving
This module works by exposing endpoints through a Kubernetes service allowing the applications to be invoked through REST endpoints. To provide the routing capabilities needed to expose the service, Knative uses Istio as well as a set of CRDs (Custom Resource Definitions) explained in the following diagram:
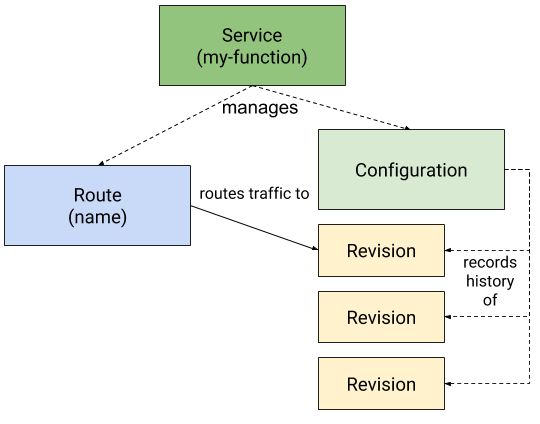

Image taken from: https://knative.dev/docs/serving/
CRDs Involved
Service: It is the component that handles the lifecycle of the application. It is also the component responsible to define other CRDs ,like the routes, and to manage the different versions of the application, by default it points always to the latest revision deployed.
Route: It is the component that handles the routing between the service endpoint and a concrete revision of the application. This is the component that uses Istio, and thanks to it, it can split traffic between different revisions to implement blue-green deployments or canary releases.
Configuration: This component stores the configuration needed for the application, decoupling it from the code.
Revision: This component is a pointer to a specific version of the tuple: code, configuration of the application, and it is immutable.
Eventing
This module uses a message broker to produce and consume events and this way allows a developer to deploy event driven applications. This module offers different ways of communications such as:
- Produce only: It sends events to the broker directly using a POST Rest endpoint.
- Consume only: It uses a trigger to filter out the events of a certain type stored in the message broker and send them to the application through a user-defined POST Rest endpoint. This process is shown in the diagram below.
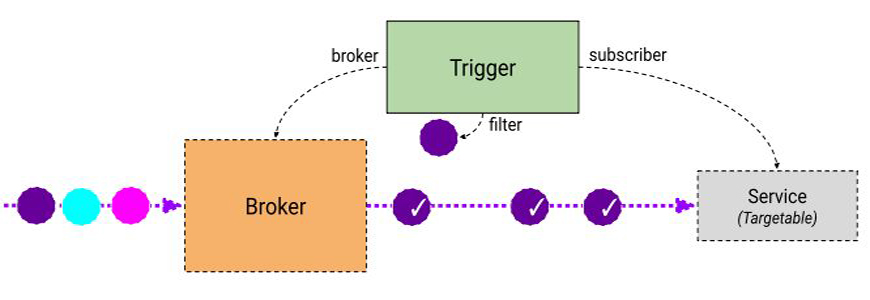

Image taken from: https://knative.dev/docs/eventing/
- Event transformation: It is used to define complex pipelines to transform events using channels and subscriptions.
CRDs Involved
Broker: This is the component responsible for receiving the events, store them, and send them to the services using the trigger. A broker has a specific type defined by the channel.
Trigger: This is the component that listens to the broker and when an event is received, applies its filter and sends the event to the application subscribed to it. To do this it uses an endpoint defined by the application in the subscription object.
Channel: It is the implementation of the broker. It can be Kafka, in memory, GCP pub/sub, or others…
Subscription: This is the component that defines, for every application subscribed to a particular channel, what is the endpoint that has to be invoked by the trigger when an event passes the filter defined in it.
Getting started with Knative
How does it work?
Knative uses a custom Kubernetes operator to create the different CRDs as well as other Kubernetes API objects like deployments, pods, or services needed to run serverless workloads.
This operator also creates virtual endpoints (endpoints not related to any pods) used to listen to requests that trigger the deployment creation when the first request reaches it. This way Knative can scale the applications to 0 when the application is not used.
The downside of this feature is that the response time of the first request is much higher because it has to wait for the deployment to be created and the pod to respond. The following requests will be much faster because the deployment is already created. Then, when a certain time threshold is reached without any new requests, the application scales down to 0 again, and the deployment is deleted.
Conclusion
As we have seen in this article, the serverless philosophy has many advantages compared to the traditional deploy and run model. One of them is to forget about maintenance, upgrades, and security patches of servers. Another important feature is the ability to scale down the applications to 0 when they are not used and this way save money paying only when they are used. This can save a lot of money especially in applications with irregular load over time.
The advantage of Knative over other serverless platforms is that it avoids the vendor lock-in by offering a platform developed over Kubernetes that can be deployed in any cloud that supports Kubernetes without changing anything.
Several companies have already taken advantage of Knative and currently offer commercial serverless platforms based on Knative ready to be used. Some of them are Gardener, Google Cloud Run, Managed Knative for IBM Cloud Kubernetes Service, Red Hat Openshift Serverless, Pivotal Function Service (PFS), or TriggerMesh Cloud





