
Certified distribution
Stratio is delighted to announce that it is officially a Certified Spark Distribution. The certification is very important for us because we deeply believe that the certification program provides many benefits to the Spark community: It facilitates collaboration and integration, offers broad evolution and support for the rich Spark ecosystem, simplifies the adoption of critical security updates, and allows the development of applications valid for any certified distribution – a key ingredient for a successful ecosystem.
This post is a brief history of how we started with big data technologies until we made the shift to Spark.
When Stratio met Spark: A true love story
We started using Big Data technologies more than 7 years ago, when Hadoop was still in Beta. We did not start using Big Data technologies because we were so smart as to predict it was going to be the future of data, it was just chance and necessity.
We had a product for ORM (online reputation management). This product was collecting Internet comments about more than 400 hundred companies. After collecting all these comments we were processing them with our semantic engine, making reports, and to send alerts to our clients. With Web 2.0 the information on the Internet started to grow exponentially; all the blogs were generating millions of posts and comments. Thus, our semantic engine was taking longer to process each day, until we were not able to send the reports before 9am. We discussed ways of solving the problem, e.g., to increase the number of servers as well as other solutions. As you have already imagined, one of the solutions was to use a very incipient technology called Hadoop to optimize our semantic engine processing. We were young and brave (we still are) and we followed that path. It was really hard; Hadoop Beta had a lot of bugs. After several months, we were able to implement a MapReduce style program for our semantic engine and make our first test. The results were impressive; we shortened the time needed to process all the comments from 12 hours to less than 30 minutes. It was awesome; of course, we knew that the semantic processing was pretty “map reducible”, but it blew our minds anyway. That was the moment we fell in love with Big Data technology.
By 2013 we had been developing Big Data projects for more than 6 years. Those were the times when we were implementing Nathan Marz Lambda architectures combining Hadoop and Storm. We achieved fantastic goals, and our clients were impressed with the results. But we also found some limitations: there were no interactive queries nor real-time data streaming analysis. And the projects were becoming more complex to develop, deploy, and to support. So we were looking for a better way and technology to serve our clients, and hence we found Spark.
Spark
We started using Spark in 2013. With the in-memory processing and the elegance of the architecture we are able to provide incredible power and possibilities with maximum simplicity – it was just awesome. We decided to incorporate Spark in our platform before it became an Apache Incubator project because we saw that the concepts behind it, and the improvements and possibilities were so huge that we did not have any doubt that it was the new “Hadoop Map Reduce” engine. During 2013, Spark streaming was added to Spark, and in 2014 Spark became an Apache Top-Level Project, so time has proven us right. In fact, we did not incorporate Spark keeping Hadoop Map Reduce; we completely replaced Hadoop Map Reduce, creating a Pure Spark Platform.
Stratio: A pure Spark enterprise platform
To include spark in our platform so early was a bit risky, but to become such early adopters has had a big return for us. We have been able to create a pure spark enterprise platform in record time and our first version was launched at the end of March.
Thanks to Spark and our Pure Spark approach, our Enterprise Platform was leaner and simpler than former platforms:
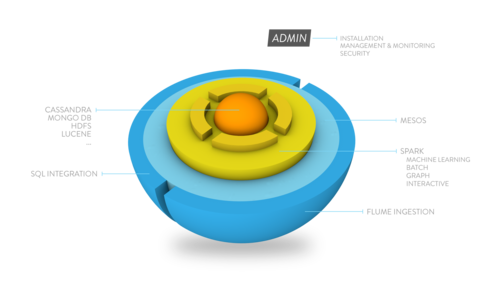
We have integrated some of the Hadoop tools such as Flume, and also created some modules that were needed in order to have a real Enterprise-ready Spark platform.
Admin
The first one was our admin module. “Admin” is responsible for:
- Installation, Full deployment on-premise, and cloud
- Platform management and monitoring
- Security
- System Dashboards and Reporting
- System alerts
CrossData
After 7 years doing Big Data projects, we have seen once again how difficult it was for the clients to use Big Data technology, so we tried to simplify the use of Big data technology with three main objectives in mind:
- Allow the clients to use the system just using SQL. Nothing else needed.
- Combine the best processing engine with the best NoSQL Databases, to leverage the benefits of both worlds.
- Allow combination: Different storage systems ( HDFS, MongoDB, Elastic Search…) or data stored with data streaming entering in real-time into the system (past data with current data)
In order to achieve the goals described above we created “CrossData”:
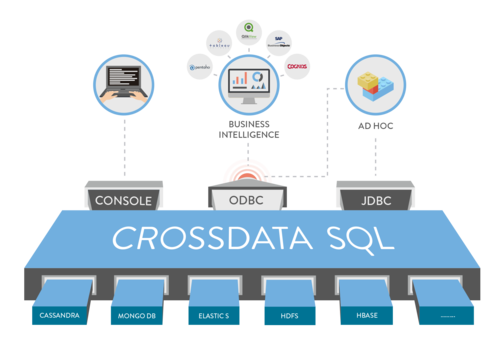
“CrossData” is not only an easy SQL interface; it combines data, and also uses Spark to complement the NoSQL Databases with features not implemented in their APIs, e.g., make SQL joint in MongoDB or to allow any other before “impossible” sentences.
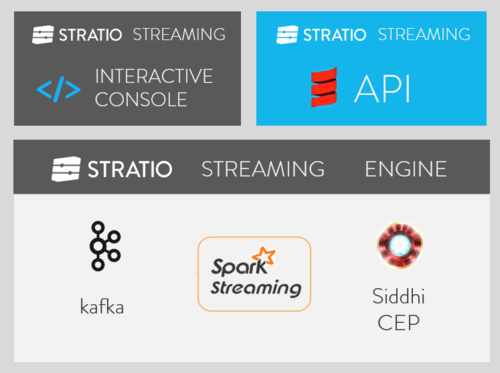
Spark Streaming and Stratio Streaming
We have been using Spark streaming from the very beginning. In fact, we were replacing Storm in some of the projects we developed before Spark Streaming was launched.
We at Stratio think that Spark Streaming is the perfect tool to build a powerful solution for interactive complex event processing. Therefore we have combined Spark Streaming with complex engine processing (CEP) and Kafka creating Stratio Streaming:
Use cases
We only use Spark for processing, and not just in POCs but for real projects for big companies. Comparing the projects we were doing with former technologies with the ones we are doing now with Spark, we can point out several benefits:
- Developers: Easier and faster development
- System Engineers: Easier deployment and cost reduction support
- Clients and Business: More value with less complexity
We have measured the improvement of using Spark against the previous Big Data platforms for some of our Banking Clients, and Spark has been up to 20X faster, reducing hours of processing down to minutes. Here are some examples of real use cases of Spark and the Stratio platform:
- NH Hotels: They wanted to aggregate customer satisfaction data and guests’ reviews from social networks and combine them with financial data. Using the Stratio platform they were able to manage about 200K reviews per year. The Quality Focus Online tool is used by more than 400 hotel directors worldwide and 15% of the variable income of employees depends on its measurements. Additionally, they have considerably reduced their negative reviews by using this tool.
- Telefonica: The cybersecurity group has the necessity to analyze all their logs in order to detect or even prevent possible hacking attacks. After checking many of the existing technologies they decide to use the Stratio platform for such a task. Currently, they can take profit from all the available information coming from different sources (access logs, DNS, email, reviews, etc) by detecting and resolving possible security weaknesses or exploits and generate exhaustive informs.

The future
We see Spark as the evolution of Hadoop Map Reduce, extended, and with none of the previous limitations, so we are just at the beginning of a revolution for Big Data processing. And it is only improving with new modules and possibilities every year that will make products and projects which were once impossible with former technologies a reality. So stay connected because this adventure has just started.


