
A follow-up to this post will be held at the Spark Summit East in Boston in February. Find out more.
***
Amongst all the Big Data technology madness, security seems to be an afterthought at best. When one talks about Big Data technologies and security, they are usually referring to the integration of these technologies with Kerberos. It’s true however that this trend seems to be changing for the better and we now have a few security options for these technologies, like TLS. Against this backdrop, we would like to take a look at the interaction between the most popular large-scale data processing technology, Apache Spark, and the most popular authentication framework, MIT’s Kerberos.
What is Kerberos?
Writing about Kerberos is not the main objective of this post, because it could be the main subject of a full post itself. We are also assuming that our loyal readers are aware of Spark’s functionalities and main characteristics so we are not even venturing there. Kerberos is rather more unknown however so we would like to briefly explain what this technology is.
Kerberos is a secure authentication method developed by MIT that allows two services located in a non-secured network to authenticate themselves in a secure way. Kerberos, which is based on a ticketing system, serves as both Authentication Server and as Ticket Granting Server (TGS).
Kerberos has become the standard authentication method within the Hadoop ecosystem. For this reason, most Big Data technologies have adopted it as their authentication method. Spark is not an exception and some of its cluster managers use Kerberos to get authenticated access to datastores such as HDFS or HBase.
How does Spark Interact with the storage systems?
As just mentioned, Kerberos allows us to properly authenticate interactions between Spark’s cluster managers and remote storage systems. But exactly when and where does Spark interact with these storage system?
Spark calculates the level of parallel computing using the base RDD parallelism level. When this base RDD is based on a storage system – which is usually the case – the Spark Driver has to interact with the Storage system in order to use its parallelism strategy and get the proper parallelization.
The Spark Executor interacts with the final storage system. If we are to use Kerberos as an authentication method to access it, we need to make the connection using an authenticated user: We have to use a Kerberos ticket to authenticate access to the stored resources.
To illustrate both of these interactions, here is a diagram that shows how Spark interacts with HDFS in a simple process that starts with reading a csv folder and transforming it into parquet format and then storing it in another folder:
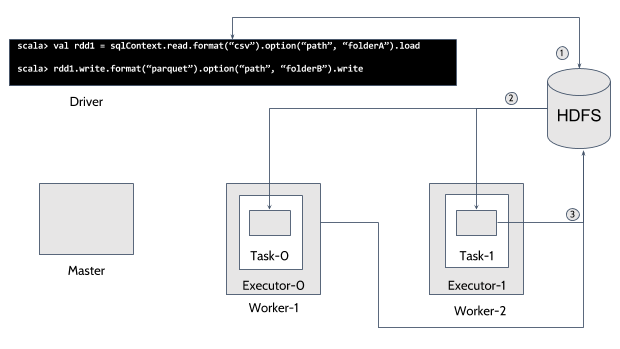
In the diagram, we have numbered the interactions of a Spark Job with HDFS according to their order. As described in the previous paragraphs, the first thing that Spark does is to communicate with the final Storage System to get the proper parallelism information. This step (1) is done by the Driver. This means that every Job that loads (2) or stores (3) data from a Kerberized resource must have a Driver that is properly registered with Kerberos.
The other operations – either read or write – are done by the Spark Executor, that is launched inside a Spark Worker independently of its resource manager. All the Tasks executed inside the Executor must be launched by a user authenticated in Kerberos.
What we can see here is that the Spark Driver and Spark Tasks need to be executed by users properly identified in Kerberos, so that the Security solution can be achieved independently of the resource manager. The reality right now is quite different however.
The current Kerberos & Spark situation
Looking at the Spark github repository and the security solution, it is clear that only YARN has been adapted for using Kerberos. If we dig further in github, we notice that Mesosphere has developed a different solution for Mesos.
YARN
The YARN solution is the eldest one and the one that seems to have been used as the initial point for Mesosphere. It is based on YARN’s solution for Map&Reduce jobs, but has been adapted for Spark.
The YARN solution is based on the Hadoop Token delegation system that is Hadoop’s adaptation of the Kerberos Ticketing system. The process starts with a Kerberos TGT (ticket-granting ticket), but then stops using the Kerberos token system to use Hadoop’s delegation tokens (Hadoop KDC). This means that if some technologies are not able to use Hadoop KDC – Apache Cassandra for instance – the method will not work. What’s more, this method needs HDFS to be a part of the cluster, or to at least provide one that is accessible in every cluster host.
The location of secrets, in this case Kerberos’ keytab, must be either as the resource or in each machine of the cluster, in the same path. And the Kerberos’ principal must be declared part of the Spark Submit arguments, with the option –principal in the command line.
How it works
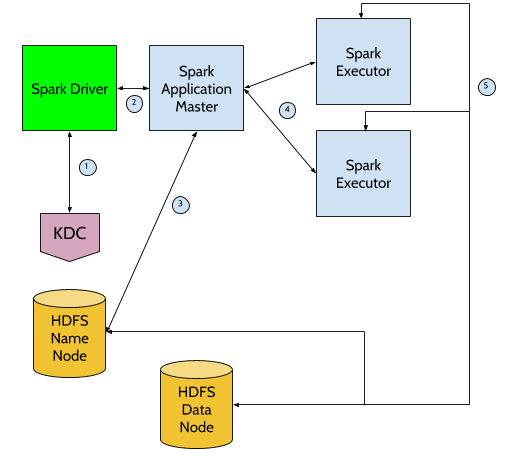
- Spark Driver gets ticket services for Spark using User1 as principal
- Spark Driver executes spark-submit with options –keytab and –principal
- Spark gets Namenode service tickets
- Yarn launches Spark Executor using User1’s identity
- Spark reads and stores data from and to HDFS using User1’s delegation Tokens.
Conclusion
The YARN solution provides us with a method for loading and storing data in HDFS or HBase, using Spark with three conditions: The first one is evident – launching the job using YARN as resource manager – the second is that HDFS must be present in the cluster and the last is that only one user is allowed to launch jobs for each SparkContext. If we had a long term SparkContext with several users launching jobs to a Kerberized resource, this method would not work.
MESOS
Mesos is the technology that is most strongly bound to Spark. Spark’s creator Matei Zaharia was a student at AMPLab, UC Berkeley where he heavily contributed to both Mesos and Spark.
Considering this, one could imagine that Spark and Mesos are a perfect match, even in security. But, as we said before, in all this Big Data ecosystem, security comes, at best, second place and Mesos has not yet been integrated with Kerberos. At the moment, there is a full integration of Spark, Mesos and Kerberos developed by Mesosphere but this integration is not part of the Apache Spark distribution. It needs to be downloaded and compiled from its its GitHub repository.
How it works
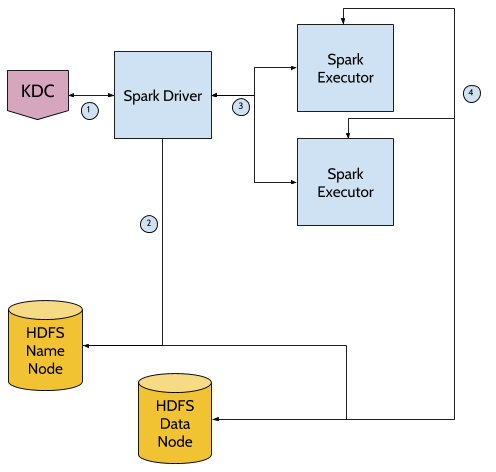
- Spark Driver starts the Spark Job
- Spark Driver gets ticket services for Spark using User1 as principal
- Spark Driver executes spark-submit with options –principal and –keytab or –tgt
- Spark gets Namenode service tickets
- Mesos launches Spark Executor using User1’s identity
- Spark reads and stores data from and to HDFS using User1’s delegation Tokens.
Conclusion
Like YARN, Mesos’ solution provides us with a method for launching Spark jobs that load or store data into HDFS. The following three conditions prevail:
- Launch the job using Mesos as resource manager
- HDFS must be present or accessible for each cluster’s machine
- Only one user is allowed to launch jobs for each SparkContext
Mesos’ solution doesn’t force us to have a keytab and allows us to use the Kerberos’ TGT (Ticket-Granting Ticket) resulting from a login prior to execution.
STANDALONE
With Standalone as a resource manager, there are no developments that allow us to access or store data using Kerberos as authentication method.
Conclusion
We have covered the current situation in terms of the integration of Spark and Kerberos. It would be possible to use either YARN or Mesos to access HDFS using Kerberos as authentication method. But if your Use Case needs to use Spark as a resource manager, Standalone as a master, or if you need several concurrent users using a long term SparkContext, neither of these solutions would work.
At Stratio we have come up with a solution to this problem using Spark, HDFS, Kerberos and Stratio’s XData.
Catch us (Abel Rincon and Jorge Lopez-Malla) at Spark Summit East in Boston this February to find out more.


