
Introduction
Nowadays, there are a lot of Big Data query engines available. Some companies struggle to choose which one to use. Benchmarks exist, but results can be contradictory and thus difficult to trust.
One Big Data query engine that is frequently mentioned is Presto. We wanted to find out more about its potential and decided to compare it with Crossdata in a controlled environment, given that Crossdata is a data hub that extends the capabilities of Apache Spark. We detected that the most popular persisting layers in our projects are Apache Cassandra, MongoDB and HDFS+Parquet, but that MongoDB is not supported by Presto. The benchmark was therefore carried out with Apache Cassandra and HDFS+parquet only.
Crossdata provides additional features and optimizations to the SQLContext of Spark through the XDContext. It can be deployed as a library of Apache Spark or using a Client-Server architecture where the cluster of servers form a P2P structure.
In the first case, these additional features include:
● Native access to Apache Cassandra, MongoDB and Elasticsearch (resolve queries without using Spark resources)
● Mixing data from different data sources
● Mixing data from batch and streaming with an SQL-like language
● Metadata discovery (importing all tables from a datastore using only one command)
● Logical views
● Persistent metadata catalog (no need to register all tables in every session)
● Creating tables in the datastores
● Data insertions.
When using the P2P deployment, Crossdata offers:
● JDBC/ODBC self-contained
● Flat view of subdocuments and arrays
● High-availability
● Load balancing
● User groups
● Apache Zeppelin interpreter
● Query builder
In the near future, the Crossdata team will be implementing more features such as:
● Global indexes (usage of inverted indexes).
● API Rest.
● Spark procedures from a SQL-like language
● Drop tables in datastores.
● Usage of statistics for query planning optimization.
Why compare?
One of the main goals of the comparison between Crossdata and Presto is to check their behaviour when launching derived TPC-DS queries, which allows us to check their performance in Big Data environments. Two persistence layers were used for the benchmark: Cassandra and HDFS+Parquet. Cassandra is a NoSQL database ideal for high-speed, online transactional data while the combination of HDFS+Parquet focuses on data warehousing and data lake use cases. The benchmark covers these different scenarios, but both fall within the Big Data landscape.
It is important to highlight that these tests work with a single-user scenario and that no secondary indexes of Cassandra were used. Currently, Crossdata takes advantage of Stratio’s Cassandra Lucene Index in order to resolve the queries natively when possible.
The queries used for this benchmark give some insight into how Crossdata and Presto work when large volumes of data are examined, queries of various operational requirements and complexities (e.g., ad-hoc, reporting, iterative OLAP, data mining) are executed, and high CPU and IO load are needed.
Environment
As mentioned before, the benchmark was executed in a controlled environment. The Crossdata team made use of 8 Huawei XH628 servers located in our European offices. The following hardware was used:
● 2 Intel Xeon E5-2630V3 processors with 8 cores and 2´4GHz.
● 64 GB RAM DDR4.
● 4 SATA disk with 1TB at 7´5k.
● 2 10GbE interfaces
Before the benchmark, some configurations were tested with Presto and Crossdata, adjusting their parameters for the best stability and throughput results.
Both Presto and Spark had 32 GB available in the JVM per node, with one server acting as Master, and the other seven acting as workers.
In the end, this was the configuration used:
● Presto
○ 112 cores in total (shared with Cassandra)
○ 134.4GB available for executing queries
● Crossdata
○ Spark Cluster (Standalone deployment)
■ 66 cores in Spark + 66 cores in Cassandra
■ 224GB available for executing queries
The reason Presto has less available memory than Spark, is because it automatically reserves 40% of the available JVM memory as heap for internal use in the cluster (7*32GB = 224 GB -> 224 GB * 0.6 = 134.4GB available for all queries executed in the cluster). The memory in Spark works differently given that it doesn’t reserve a part of the memory statically to manage the cluster resources or operations. It just reserves and frees the memory as it is requested by the cluster so that it is more elastic in the memory management.
The TPC-DS dataset used had a size of 840GB and it was created with tools respecting the official metadata of the specifications and creating all the tables required by the standard.
The subset consists of the following 21 queries: q7, q11, q13, q15, q19, q25, q26, q29, q31, q43, q48, q55, q59, q66, q74, q76, q78, q84, q85, q91 and q93. These 21 queries were chosen because they are supported grammatically by both frameworks and because they represent a heterogeneous subset of the TPC-DS queries. Thus, different aspects and capabilities of resolving different types of queries were tested.
However, for the comparison with Cassandra, a different set of queries were used:
● q84 from the derived TPC-DS set of queries mentioned above.
● n1: select * from customer
● n2: select * from customer where c_customer_sk = 9808094
● n3: select * from store_sales limit 5000
● n4: select * from store_sales where ss_item_sk = 51097 and ss_ticket_number = 36448921
Results
The first thing to be noticed is that Presto didn’t resolve all queries because it threw an OutOfMemoryException and, therefore, only some queries of the 21 initial queries were valid for the comparison. It’s important to mention that different configuration parameters were tried in order to maximize the number of queries resolved by Presto and, finally, the configuration mentioned above was the most successful one.
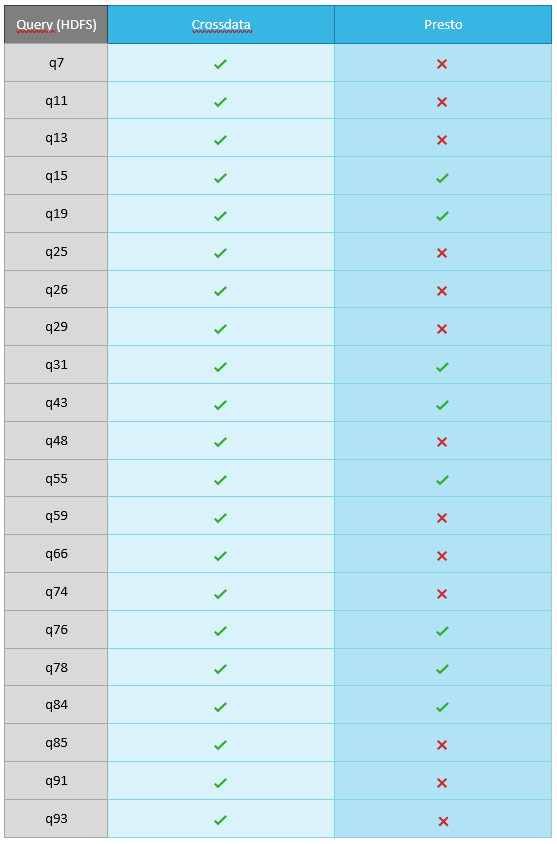
Only the following queries were used for the Benchmark with HDFS+Parquet: q15, q19, q31, q43, q55, q76, q78 and q84.
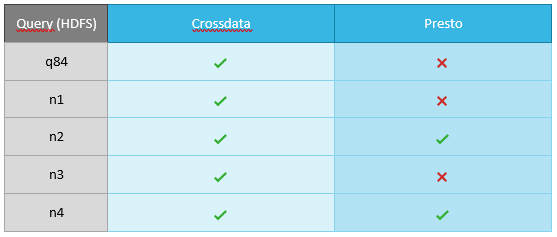
Only the following queries were used for the Benchmark with Cassandra: n2 and n4.
Again, we have to keep in mind that this benchmark was performed in a single-user environment.
The following graph represents the results with HDFS+Parquet with the aforementioned set of queries:
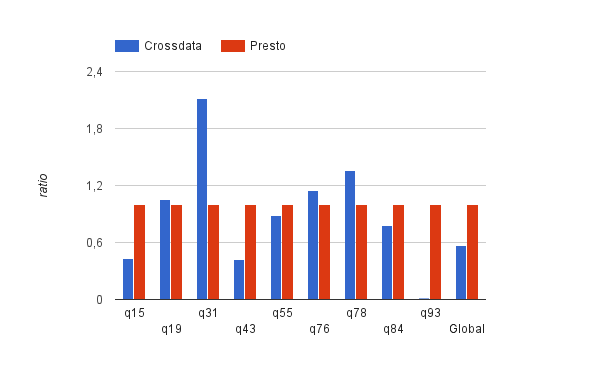
Due to the difference in resolution time of the different queries, the above graph has been created using the Presto time for every query as the referent ratio (fixed to 1) versus the query resolution time in Crossdata. As shown, Crossdata resolves queries faster 5 out of 9 times and on average, Crossdata obtains a global ratio that represents half of the one of Presto, approximately.
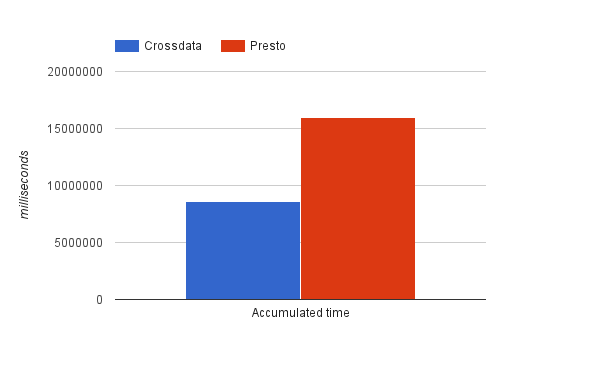
The above chart represents the total time of the 9 queries in both systems. Again, this figure shows that the accumulated time for resolving the queries in Presto is twice that of resolving the queries in Crossdata.
The following graph represents the results with Cassandra with the aforementioned set of queries:
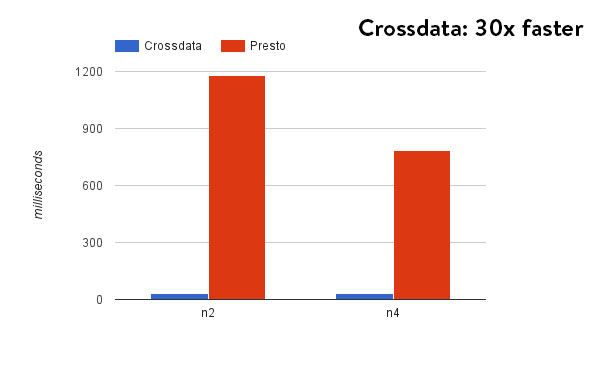
The above chart represents the resolution time of Presto and Crossdata with the 2 aforementioned queries on Cassandra. In this case, Crossdata executes these 2 queries natively, that is, Crossdata doesn’t make use of the Spark cluster because the Crossdata planner identifies that both queries can be resolved using the direct access to Cassandra.
Conclusions
The first thing to highlight is that this benchmark doesn’t take into account the queries that couldn’t be resolved by Presto. In most cases, Presto threw an OutOfMemoryException, which is quite frustrating for the aggressive usage of the memory that Presto requires. On the other hand, Apache Spark behaves much more reliably given that, before having a problem with the memory space, it leverages the space in disk in a very efficient way. We admit that Presto might have been configured in a more effective way, but, even after spending days reading the documentation, we didn’t find any better way to do it. This makes the tuning of Presto a very difficult task and, in many cases, requires very powerful environments with a large amount of resources, which contradicts the mantra in Big Data systems about using commodity hardware.
In addition, even when Presto is able to resolve the query, the resolution time is longer in comparison with Crossdata when data is stored in HDFS with Parquet format. If you look closely, Crossdata is a little slower than Presto when resolving low latency queries – by about a few milliseconds. However, when executing iterative OLAP queries, Presto takes much longer than Crossata in resolving the query, therefore, the penalty is about seconds with heavy load calculations.
By using Crossdata and Presto with Apache Cassandra, the results show that Crossdata, with the native access, and Apache Spark, with the push-downs of filters, make a better use of the datastore capabilities in order to have a better throughput.
Crossdata is therefore the more suitable option in most cases and is more reliable than Presto in all of the scenarios. Crossdata is faster for cases where native access is going to be used.
This post was written by Stratio’s Crossdata team: Miguel Angel Fernandez (@miguel_afd), Pablo Francisco Perez (@pfcoperez), Unai Sarasola, David Arroyo, Juanjo Lopez (@Orcrsit) and Hugo Dominguez (@Huguito1906)


