
Let us suppose that we start to develop a webserver for our IOT App with a few endpoints, like POST for receive events, GET devicesBySensorType, GET all, and PUT for update device metadata, etc.
At first, a cache for common data could seem like a secondary issue, but if we start to think long term and if we want to improve performance and/or to decrease response time (e.g when a service retrieve data from a database), we realize that a cache is a mandatory requirement.
An initial solution could be to use the always reliable HashMap class (or ConcurrentHashMap after the first ConcurrentModificationException): this is a first attempt that, by caching objects in different maps in memory, may give us quick benefits. But it is not enough.
Hello Data Grid
With Ignite, this is simple, only add the dependency on your scala/java project:
> sbt
"org.apache.ignite" % "ignite-core" % "2.4.0"
> maven
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-core</artifactId>
<version>2.4.0</version>
</dependency>
Scala code for the example:
object IgniteSimpleDataGrid extends App {
val igniteConfig = new IgniteConfiguration()
val cacheConfig = new CacheConfiguration("ignite")
igniteConfig.setCacheConfiguration(cacheConfig)
val ignite = Ignition.start(igniteConfig)
val cache: IgniteCache[Int, String] = ignite.getOrCreateCache[Int, String]("ignite")
for (i <- 1 to 10) {
cache.put(i, s"value-$i")
}
println(s"From cache 7 -> ${cache.get(7)}")
println(s"Not exists 20 -> ${cache.get(20)}")
}
Run the class and see the output
(Note: ONLY one running Ignite instance per JVM)
Perfect, we have our first single version of Ignite Data Grid, but what if we need HA and to deploy another instance of the app? Or it may sound familiar a common situation where that metadata endpoint is related to another service and uses the same information so are in need of sharing data between the apps and, sadly, the maps cache schema solution does not work anymore.
What if I tell you that with in-memory data grid data could be distributed and every node in the cluster (forming a ring topology) can access and maintain the shared information, besides computing remote functions or custom predicates? Would you believe that this is possible? The answer is absolutely yes and here is where Ignite stands out among other solutions.
Let’s test IgniteSimpleDataGrid class with two instances(nodes) : node1 is already running so before we can start the app again (node2), we need to comment the for cycle (block in the code snippet), because node1 has already populated the cache with values and this means that node2 will only be reading from cache.
/* for (i <- 1 to 10) {
cache.put(i, s"value-$i")
} */
println(s"From cache 7 -> ${cache.get(7)}")
println(s"Not exists 20 -> ${cache.get(20)}")
Pay attention to the output in node2: the console prints almost the same data as node1 in the first example (look at the id, it is different).

And now, look at the output in node1:

Both nodes print this line:
![]()
Great!! That means that we have our Ignite in-memory distributed key-value store cluster up and running!! (more than a simple cache, and we see why).
Nodes have been self-discovered and all of them see the same data. If we start more nodes, the topology will keep on growing up, each node will be assigned with a unique id and the server number will increase ( e.g. servers =3, servers=4 , etc..)

If we stop node1, topology decreases and the rest of the running nodes print this change, because they are listening to topology change events.

Ignite implements high availability, if a node goes down, the data is then re-balanced around the cluster without any user operation involved.
Let us clarify this point.
My definition of Ignite is that it’s a distributed in-memory cache, query and processing platform for working with large-scale data sets in real-time (leaving aside, streaming processing, Spark integration, Machine learning grid, Ignite FileSystem, persistence, transactions…)
How can Ignite automagically create a cluster? Well, it provides TcpDiscoverySpi as a default implementation of DiscoverySpi that uses TCP/IP for node discovery. Discovery SPI can be configured for Multicast- and Static IP-based node discovery. (Spi = especially Ip Finder)
It means that nodes use multicast to find each other:
val igniteConfig = new IgniteConfiguration()
val spi = new TcpDiscoverySpi()
val ipFinder = new TcpDiscoveryMulticastIpFinder()
ipFinder.setMulticastGroup("228.10.10.157") // Default value = DFLT_MCAST_GROUP = "228.1.2.4";
spi.setIpFinder(ipFinder)
cfg.setDiscoverySpi(spi)
val ignite = Ignition.start(igniteConfig)
val cache: IgniteCache[Int, String] = ignite.getOrCreateCache[Int, String]("ignite")
Ignite Ring Topology
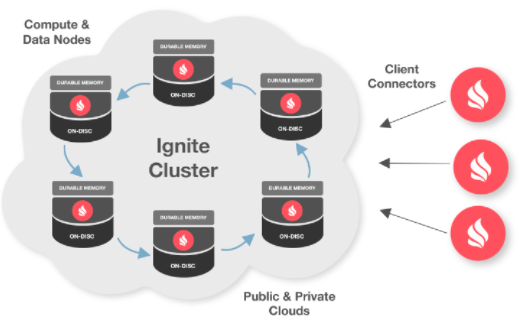
In the image the nodes form a ring of server nodes but, inside an Ignite cluster, nodes can either have roles and belong to a cluster group or they could be client nodes (this means “outside” of the ring and without the possibility of maintaining cached data. This may prove useful for external applications.
Nodes can broadcast messages to other nodes in a particular group:
val igniteCluster = ignite.cluster()
//Send to cluster remotes nodes (ignoring this) this Code
ignite.compute(igniteCluster.forRemotes()).broadcast(
new IgniteRunnable {
override def run(): Unit = println(s"Hello node ${igniteCluster.localNode()},this message had been send by igniteCompute broadcast")
}
)
As this example shows, when a node starts, it sends a message to the cluster group forRemotes and to all other nodes (except from itself) that have been configured in mode=server. You might see an exception on the first node at the beginning when the cluster has just been created but don’t worry because it is normal.
Furthermore it is possible to define nodes with your custom attributes:
igniteConfig.setUserAttributes(Map[String,Any]("ROLE" -> "MASTER").asJava)
ignite.compute(igniteCluster.forAttribute("ROLE","WORKER")).broadcast(new IgniteRunnable {
override def run(): Unit = println(s"Hello worker node ${igniteCluster.localNode()}," +s"this message had been send by ignite master node")
})
Here the node has attribute ROLE = MASTER, and broadcast only to nodes with ROLE = WORKER
Nodes with:
igniteConfig.setUserAttributes(Map[String,Any]("ROLE" -> "WORKER").asJava)
will receive the message:
As long as your cluster is alive, Ignite will guarantee that the data between different cluster nodes will always remain consistent regardless of crashes or topology changes.
So far so good: we have seen nodes, topology, cluster groups, broadcast and now let us look forward to one of the best feature of Ignite (PS: durable memory, persistence, spark RDD, streaming, transactions will be tackled in the next posts XD): SQL Queries!!
Does it sounds crazy? Yes, SQLQueries! Over your data!
Ignite is fully ANSI-99 compliant and it supports Text queries and Predicate-based Scan Queries.

Cache Queries
Before starting to play with code, a few considerations:
- Add dependency
sbt = "org.apache.ignite" % "ignite-indexing" % "2.4.0"
maven = <dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-indexing</artifactId>
<version>2.4.0</version>
</dependency>
- Tell Ignite, which entities are allowed to be used on queries, it is easy, only adding annotations to classes:
case class IotDevice( @(QuerySqlField@field)(index = true) name: String, @(QuerySqlField@field)(index = true) gpio: String, @(QueryTextField@field) sensorType: String, @(QueryTextField@field) model: String)
Here we said, that all fields are available for use in queries, and add indexes over name and gpio attributes (like in any sql database)
- After indexed and queryable fields are defined, they have to be registered in the SQL engine along with the object types they belong to.
val igniteConfig = new IgniteConfiguration()
val cacheConfig = new CacheConfiguration("ignite")
cacheConfig.setIndexedTypes(Seq(classOf[String], classOf[IotDevice]): _*)
igniteConfig.setCacheConfiguration(cacheConfig)
val ignite = Ignition.start(igniteConfig)
val cacheIot: IgniteCache[String, IotDevice] = ignite.getOrCreateCache[Int, String]("ignite")
Following the idea of IoT WebServer, for example we develop the web server and put data to the cacheIot defined above.
val temp1 = IotDevice(name = "temp1", gpio = “123ASD", sensorType = "temperature", model = "test") cacheIot.put(temp1.gpio,temp1) val temp2 = IotDevice(name = "temp2", gpio = “456ASD", sensorType = "temperature", model = "test") cacheIot.put(temp2.gpio,temp2)
Now user call method: GET/devicesBySensorType?sensor=temperature
In our IotDevice case class sensorType is valid for queries thus, we can execute this query in three ways in Ignite:
Simple sql :
val sqlText = s"sensorType = 'temperature'" val sql = new SqlQuery[String, IotDevice](classOf[IotDevice], sqlText) val temperatureQueryResult = cacheIot.query(sql).getAll.asScala.map(_.getValue) println(s"SqlQuery = $temperatureQueryResult")
ScanQuery:
val cursor = cacheIot.query(new ScanQuery(new IgniteBiPredicate[String, IotDevice] {
override def apply(key: String, entryValue: IotDevice) : Boolean = entryValue.sensorType == "temperature"
}))
val temperatureScanResult = cursor.getAll.asScala
println(s"ScanQuery = $temperatureScanResult")
Text-based queries based on Lucene indexing, here find all IotDevices where sensorType == “temperature” (the annotation on model attribute QueryTextField allow this query, if you want, Ignite supports more than one QueryTextField)
val textQuery = new TextQuery[IotDevice, String](classOf[IotDevice], "temperature") val temperatureTextResult = cacheIot.query(textQuery).getAll.asScala println(s"TextQuery = $temperatureTextResult") //all devices with sensorType = temperature
The result of queries:

Here is the full code for the example:
import org.apache.ignite.cache.query.annotations.{QuerySqlField, QueryTextField}
import org.apache.ignite.cache.query.{ScanQuery, SqlQuery, TextQuery}
import org.apache.ignite.configuration.{CacheConfiguration, IgniteConfiguration}
import org.apache.ignite.lang.IgniteBiPredicate
import org.apache.ignite.{IgniteCache, Ignition}
import scala.annotation.meta.field
import scala.collection.JavaConverters._
object IgniteSql extends App {
val igniteConfig = new IgniteConfiguration()
val cacheConfig = new CacheConfiguration("ignite")
cacheConfig.setIndexedTypes(Seq(classOf[String], classOf\[IotDevice]): _*)
igniteConfig.setCacheConfiguration(cacheConfig)
val ignite = Ignition.start(igniteConfig)
val cacheIot: IgniteCache[String, IotDevice] = ignite.getOrCreateCache[String, IotDevice]("ignite")
val temp1 = IotDevice(name = "temp1", gpio = "123ASD", sensorType = "temperature", model = "testTemp")
cacheIot.put(temp1.gpio, temp1)
val temp2 = IotDevice(name = "temp2", gpio = "456ASD", sensorType = "temperature", model = "testTemp")
cacheIot.put(temp2.gpio, temp2)
val sqlText = s"sensorType = 'temperature'"
val sql = new SqlQuery[String, IotDevice](classOf[IotDevice], sqlText)
val temperatureQueryResult = cacheIot.query(sql).getAll.asScala.map(_.getValue)
println(s"SqlQuery = $temperatureQueryResult")
val cursor = cacheIot.query(new ScanQuery(new IgniteBiPredicate[String, IotDevice] {
override def apply(key: String, entryValue: IotDevice): Boolean = entryValue.sensorType == "temperature"}))
val temperatureScanResult = cursor.getAll.asScala
println(s"ScanQuery = $temperatureScanResult")
val textQuery = new TextQuery[IotDevice, String](classOf[IotDevice], "temperature")
val temperatureTextResult = cacheIot.query(textQuery).getAll.asScala
println(s"TextQuery = $temperatureTextResult") //all devices with sensorType = temperature
}
case class IotDevice(@(QuerySqlField@field)(index = true) name: String,
@(QuerySqlField@field)(index = true) gpio: String,
@(QueryTextField@field) sensorType: String,
@(QueryTextField@field) model: String)
Partition and Replication
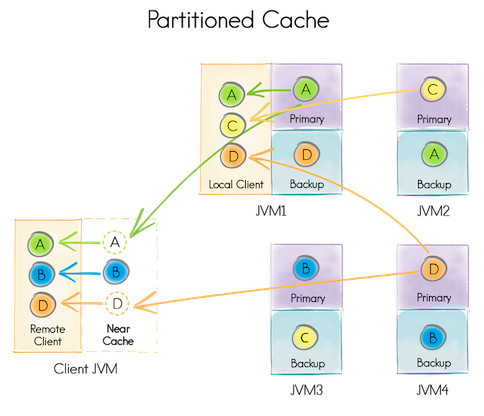
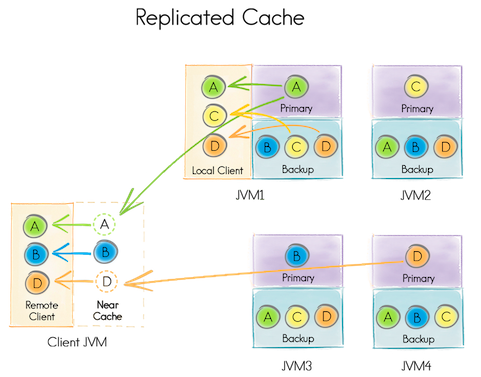
Besides having our cluster and executing queries, we might ask ourselves: where currently is our data? Ignite provides three different modes of cache operation: PARTITIONED, REPLICATED, and LOCAL:
- Partitioned: this mode is the most scalable among the distributed cache modes. In this mode the overall data set is divided equally into partitions and all partitions are split equally between participating nodes. This is ideal when working with large data sets and updates are frequent. In this mode you can also optionally configure any number of backup nodes for cached data.
cacheCfg.setCacheMode(CacheMode.PARTITIONED) cacheCfg.setBackups(1);
- Replicated: this mode is expensive because all the data is replicated to every node in the cluster and every data updates must be propagated to all other nodes that can have an impact on performance and scalability. This mode is ideal when we are working with small datasets and updates are not frequent.
cacheCfg.setCacheMode(CacheMode.REPLICATED)
- Local: this mode is the most light-weight mode of cache operation, as no data is distributed to other cache nodes.
In-Memory features
Since Ignite architecture is *memory friendly*, RAM is always treated as the first memory tier, where all the processing happens. Some benefits of this:
– Off-heap Based: Data and indexes are stored outside Java heap, therefore only your app code may trigger Garbage collection actions.
– Predictable memory usage: It is possible to set up memory utilization.
– Automatic memory defragmentation: Apache Ignite uses the memory as efficiently as possible and executes defragmentation routines in the background thus avoiding fragmentation.
– Improved performance and memory utilization: All the data and indexes are stored in paged format with similar representation in memory and on disk, which removes any need for serializing or deserializing of data.
Conclusion
Could Ignite help your distributed architectures? Would it be costly to integrate Ignite in your apps that are already in production?
There is a lot more to cover and discuss…and a lot of code to try out! We only scratched the surface of this great tool.
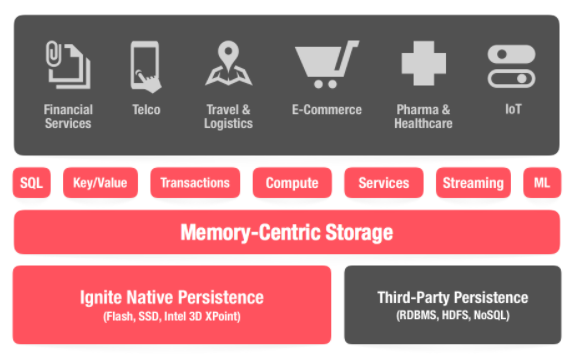
For more information, documentation, and screencasts, visit:
- Ignite Apache
- Github Apache Ignite
- @ApacheIgnite
- https://github.com/gastonlucero/ignitestratio
- Multicast in Ignite
- Wikipedia – IP_Multicast



7 Comments
A great read indeed! I am curious on how this would work if we had a larger system made up of different microservices on the same network. Some services would end up caching data which it will never require. Would it be possible to create separate clusters (per service)?
Hey Chris
Maybe you can use the client/server mode. At the beginning before Ignition.start, you can set the “client” mode, the native client nodes provide ability to connect to the servers remotely.
And in mode=server (default value) node, with attributes, you can separate your microservices logic, simply using the corresponding cluster group:
val igniteCluster = ignite.cluster().forAttribute(“ROLE”,”MICROSERVICE_X”)
igniteCluster.ignite.getOrCreateCache
Or with different multicast ip, or zookeeper configuration
https://apacheignite.readme.io/docs/cluster-config#zookeeper-based-discovery
Thank you!
Hi Gastón! Nice post, I’m becaming a big fan of apache ignite, what you can say about durable memory? performance (does it scale linearly?) It’s better than HDFS (under the same conditions..)
Hi, Leonardo!!
I’m glad to hear that you like Ignite.
Related to your question, I used the default persistence (ONLY for dto objects) , but I think that, regardless of back-end technology, the most important for a good performance could be choose between distributing and/or replicating your cache, which depends on your architecture (think an application running in two datacenter, in Europe and SouthAmerica, a replicated solution sounds better for me)
But would be interesting a benchmark between hdfs, local, and jdbc persistence
I will look for Ignite File System, based in HDFS, I don’t know if there is a way to use it as persistence.(https://apacheignite-fs.readme.io/docs/in-memory-file-system).
Thanks!!
Can’t wait for those next posts 😀
Great Article , Any Example how to use NIFI with apache Ignite ?
Hi Gaston,
Thank you for writing such a clean article. But however I still can’t understand how to distribute data. How can we be ensure that data is distributed through the nodes? I coludn’t understand Affiliate concept.